Experimental Platfrom
TL;DR
PROJECT
Designed and launched adMarketplace’s internal platform (AMPlify’s) first experimentation platform, enabling internal teams to safely test ranking models, thresholds, and configurations without engineering support. Balanced sub-1ms runtime constraints, global priority logic, and permission-based configuration control within a real-time ad environment.
ROLE
Primary UX Designer (Lead) on Project
TIMELINE
Jan 7 2026 - Feb 6 2026
PROBLEM
Teams were manually modifying live production configurations with no formal A/A/B testing framework, no deterministic traffic assignment, and no clear causal measurement—creating revenue risk, configuration collisions, and slow iteration cycles.
OUTCOME
Delivered a scalable experimentation and targeting framework that introduced structured target definitions, deterministic bucketing, priority-based override logic, and centralized logging—enabling controlled A/A testing, safer configuration rollouts, and measurable, data-driven optimization across placements and publishers.
PROBLEMS
What Wasn’t Working
Experimentation was limited to pre/post testing — one configuration one week, another the next — making it impossible to isolate variables in a fluctuating auction environment. Teams manually pushed live configuration changes with no deterministic bucketing, no clear attribution, and no protection against conflicting overrides. This created revenue risk and required constant engineering involvement.
Who It Affected
Product, ML, and Operations teams lacked a safe way to test changes. Consequently, our clients; Advertisers and Publishers, were indirectly impacted by slower optimization and less reliable model improvements.
Why It Matters
In adtech, even small configuration changes can materially impact revenue and auction performance at scale. Without controlled experimentation, decisions were reactive and risky. A formal experimentation layer enables safe testing, causal measurement, and systematic, data-driven optimization.

Tight deadline: Needed to design and align on a complex system within one month.
Highly technical requirements: Requirements came from a new Director of AI and were deeply technical.
Changing scope: Requirements were being built whilst designing.
Sole UX owner: I was the only UX voice on the project, responsible for aligning technical logic with existing design standards.
Heavy cross-functional alignment: Frequent meetings with Product, AI, and Engineering were necessary to ensure feasibility, performance compliance (<1ms), and system safety.
CONSTRAINTS

PROCESS

RESEARCH
Unlike Google Ads, which primarily experiments at the campaign level, our first milestone platform focuses on backend configuration testing — including ranking models, pricing logic, and relevance thresholds — directly within the request evaluation layer.
DECISION MAKING
APPROVED DECISIONS
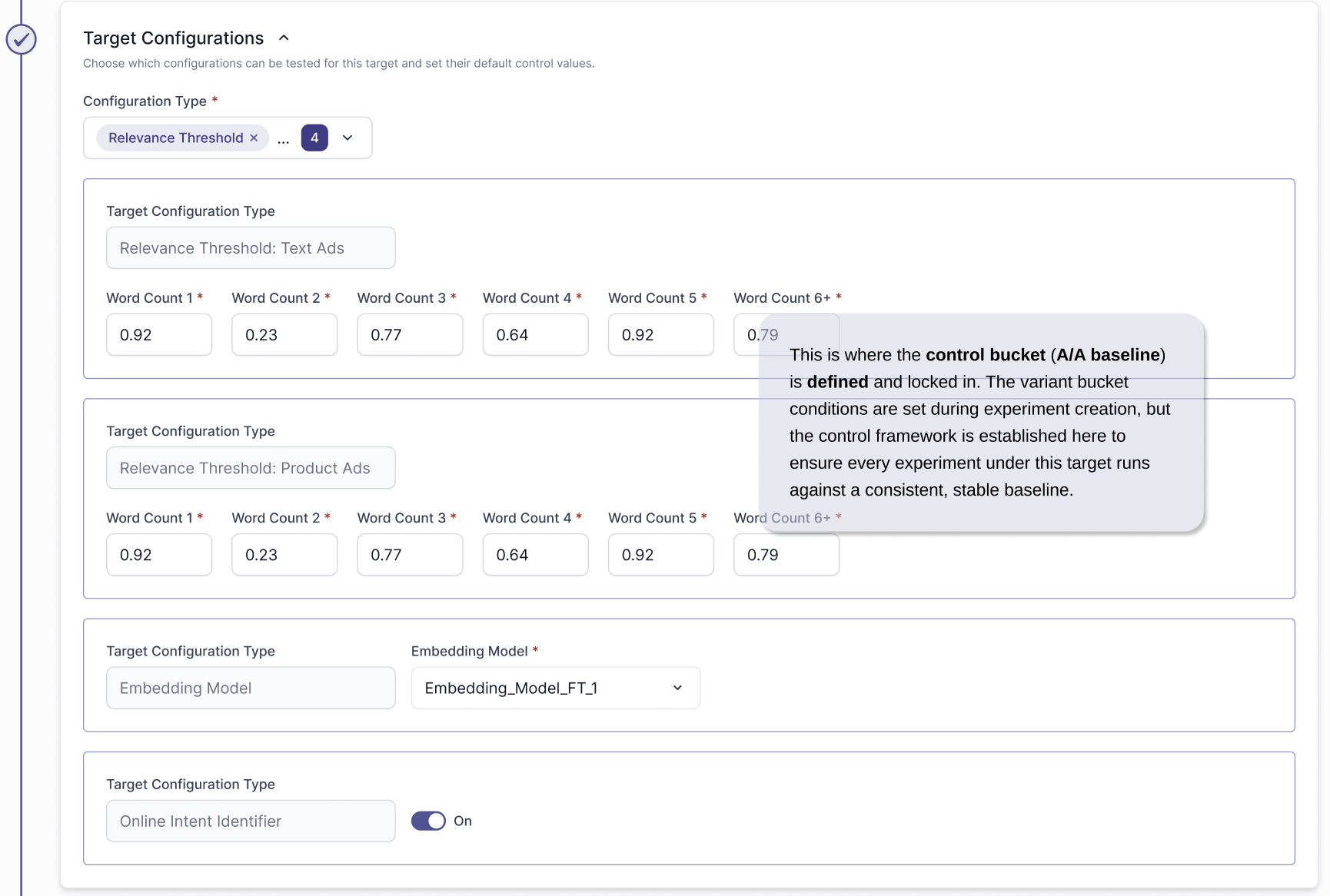
A/A versus A/B
A/A tests isolate system error.
A/B tests introduce both system + product change — so you can’t tell if strange results are caused by the feature or a broken experiment framework.
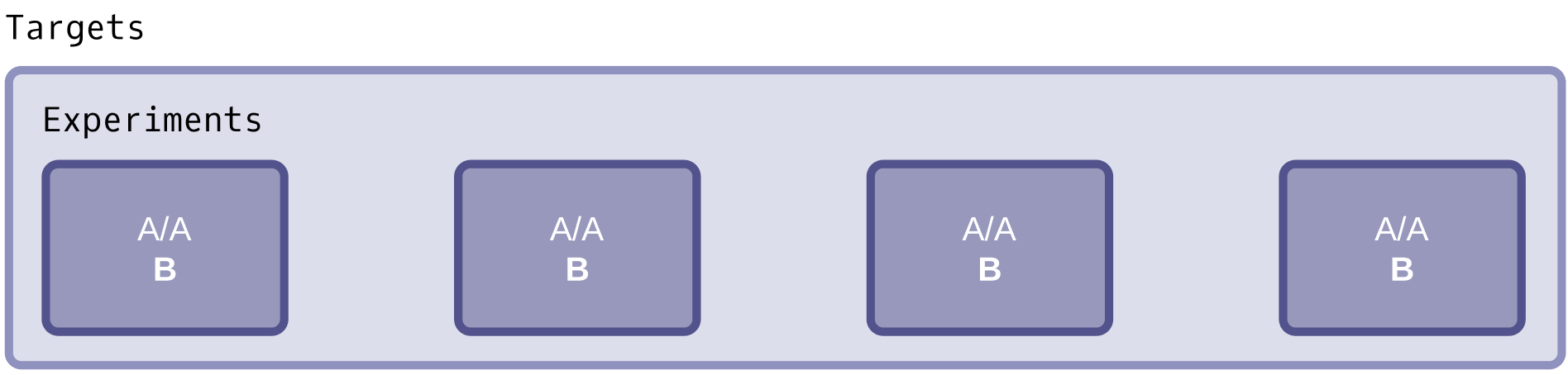
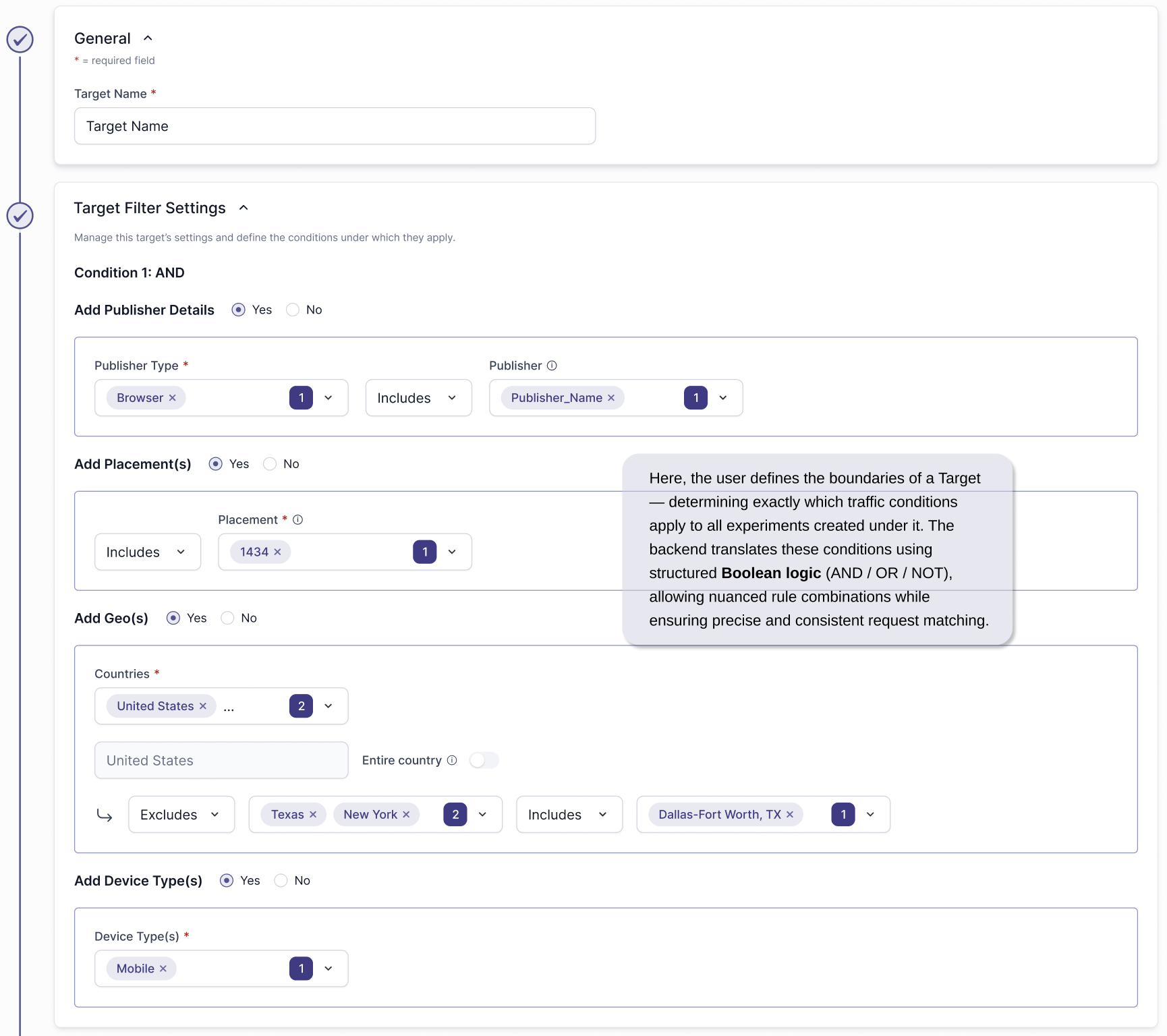
Benefit of Targets
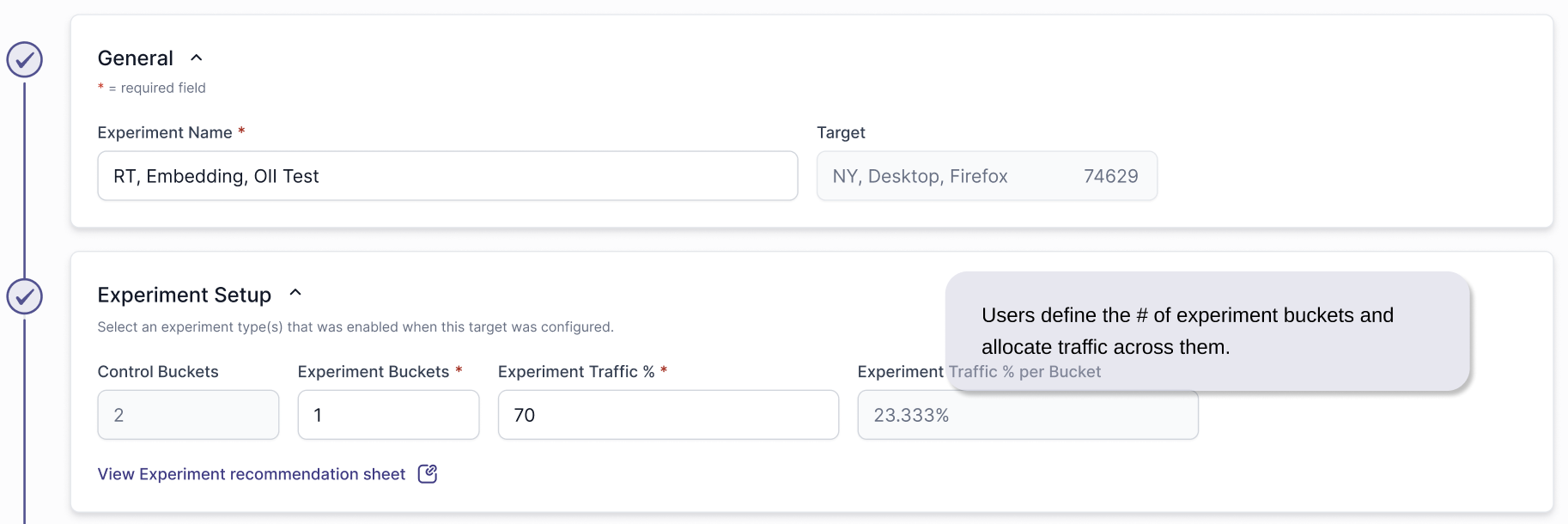
Targets define controlled boundaries for experiments.
By grouping traffic based on clear conditions like placement, publisher, country, or device, targets ensure experiments run against consistent inputs, preventing mixed traffic conditions that could distort results or misattribute performance changes.
REJECTED APPROACH 1
Before defining Targets, we explored a simplified “duplicate-and-test” approach where users could clone a configuration and split traffic between control and variant buckets. While fast and intuitive, this model lacked boundary control — experiments could run on unintended audiences or override existing logic. We ultimately prioritized accuracy and system control over speed.
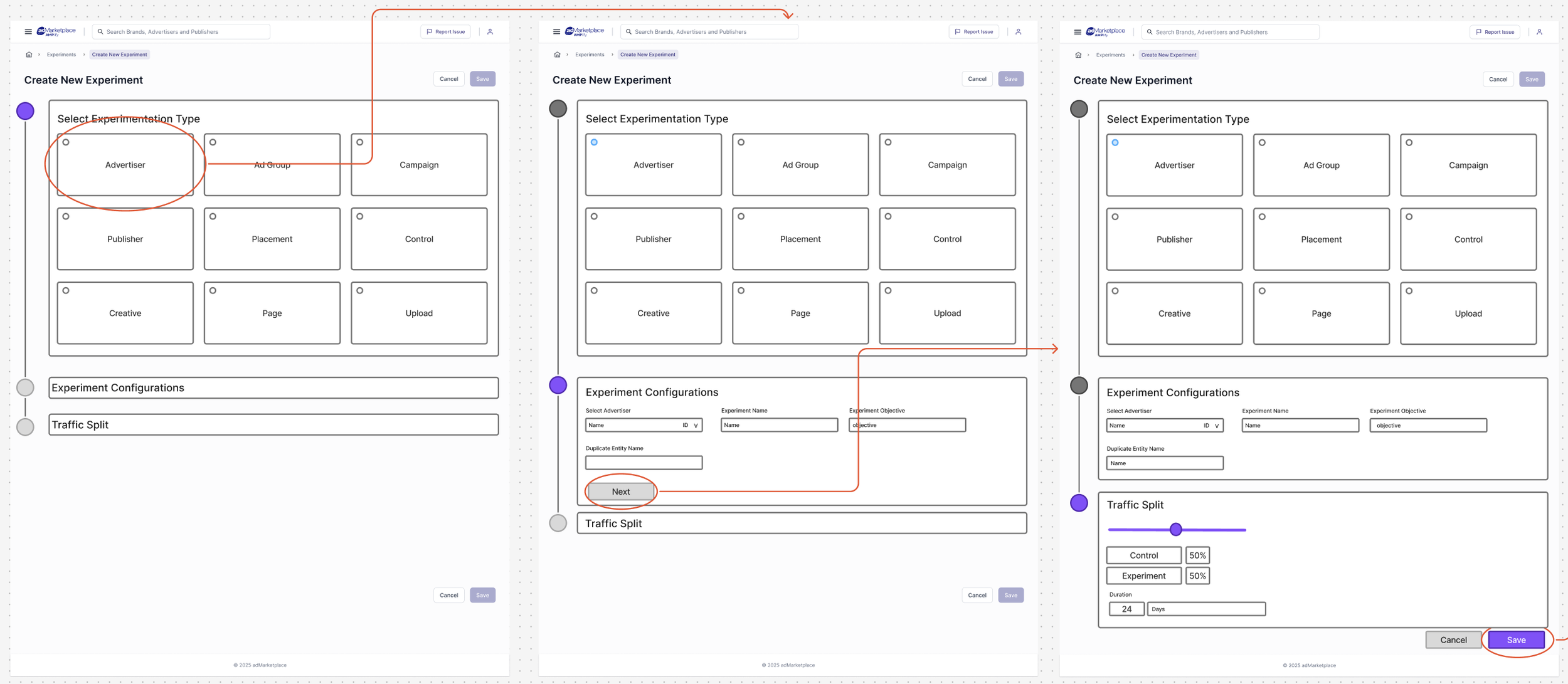
REJECTED APPROACH 2
To improve control, we introduced target configuration directly into the experiment setup flow — requiring users to define conditions before launching a test.
This improved accuracy but created scalability issues:
Every new experiment required redefining similar targeting logic, leading to repetitive workflows and limiting the ability to evolve targets into reusable, structured entities.
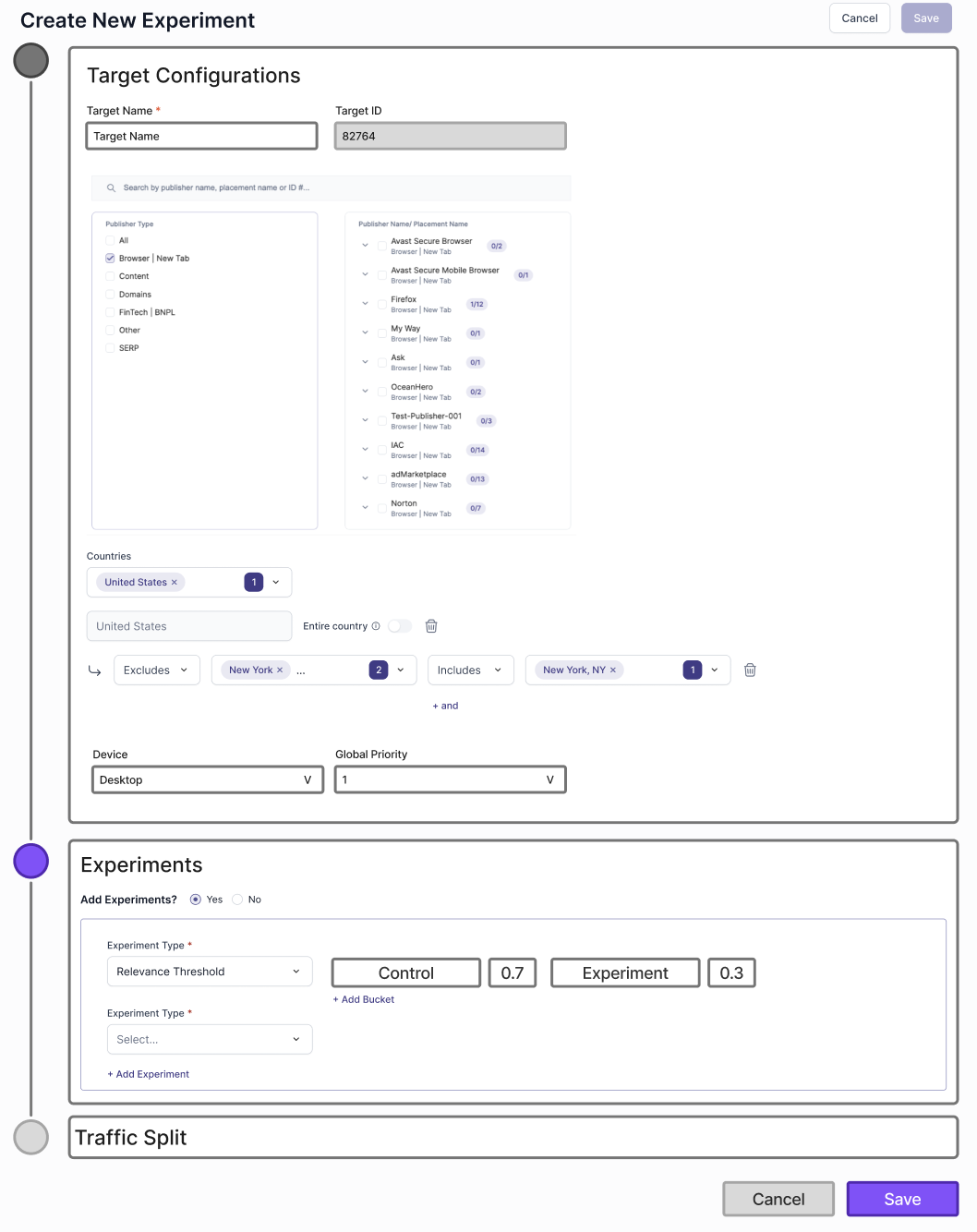
FINAL APPROVED DECISION
Separate Target and Experiment Flows
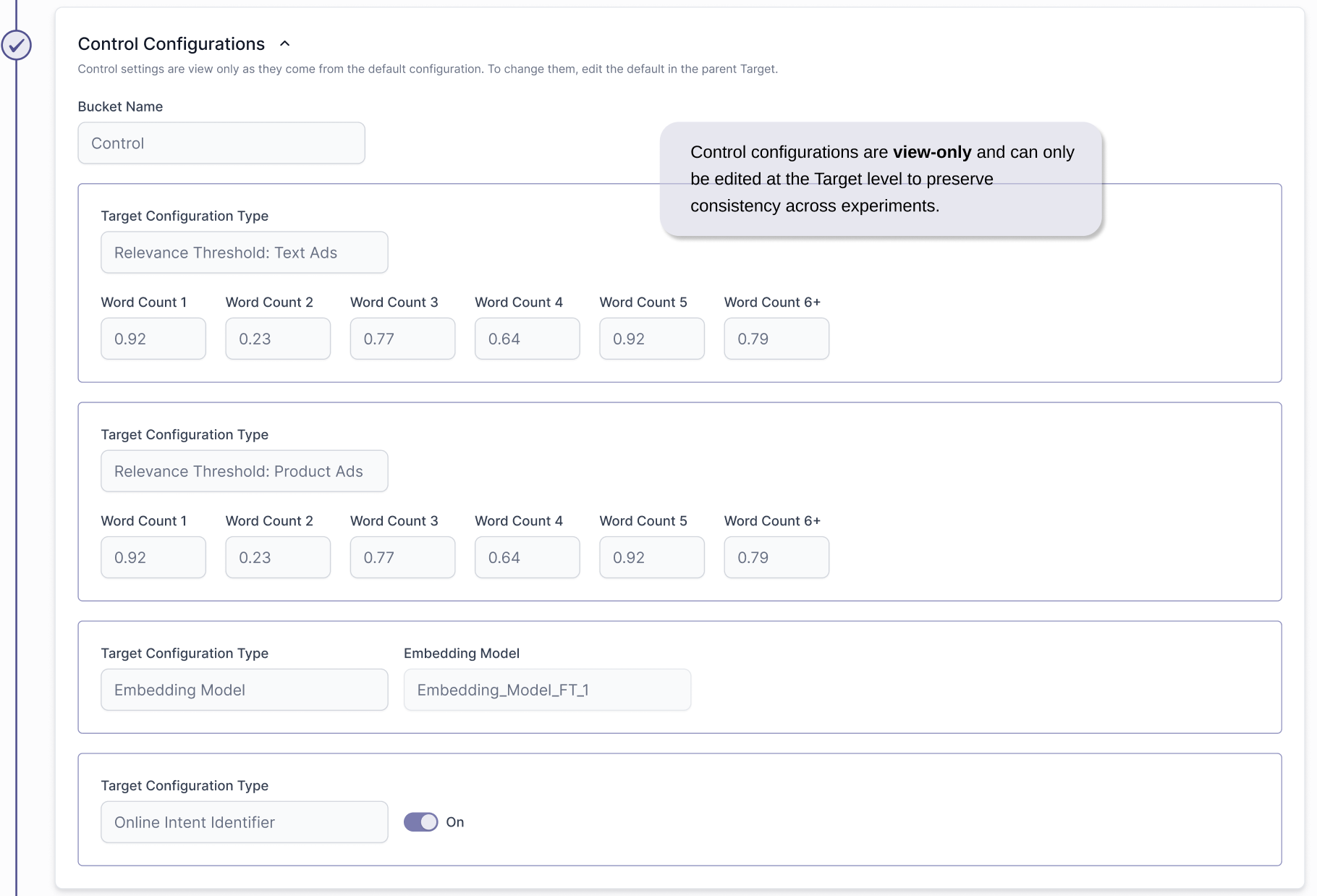
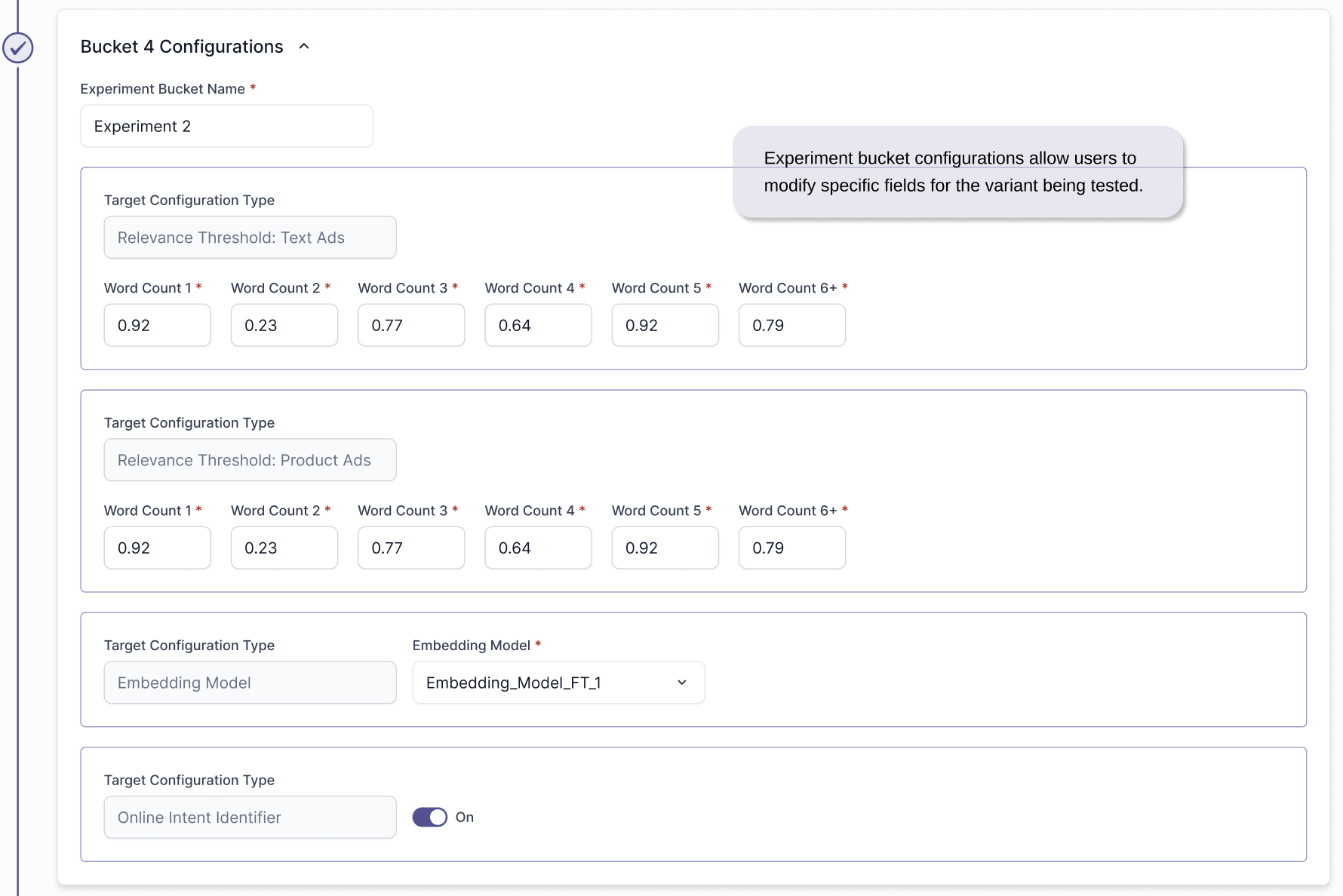
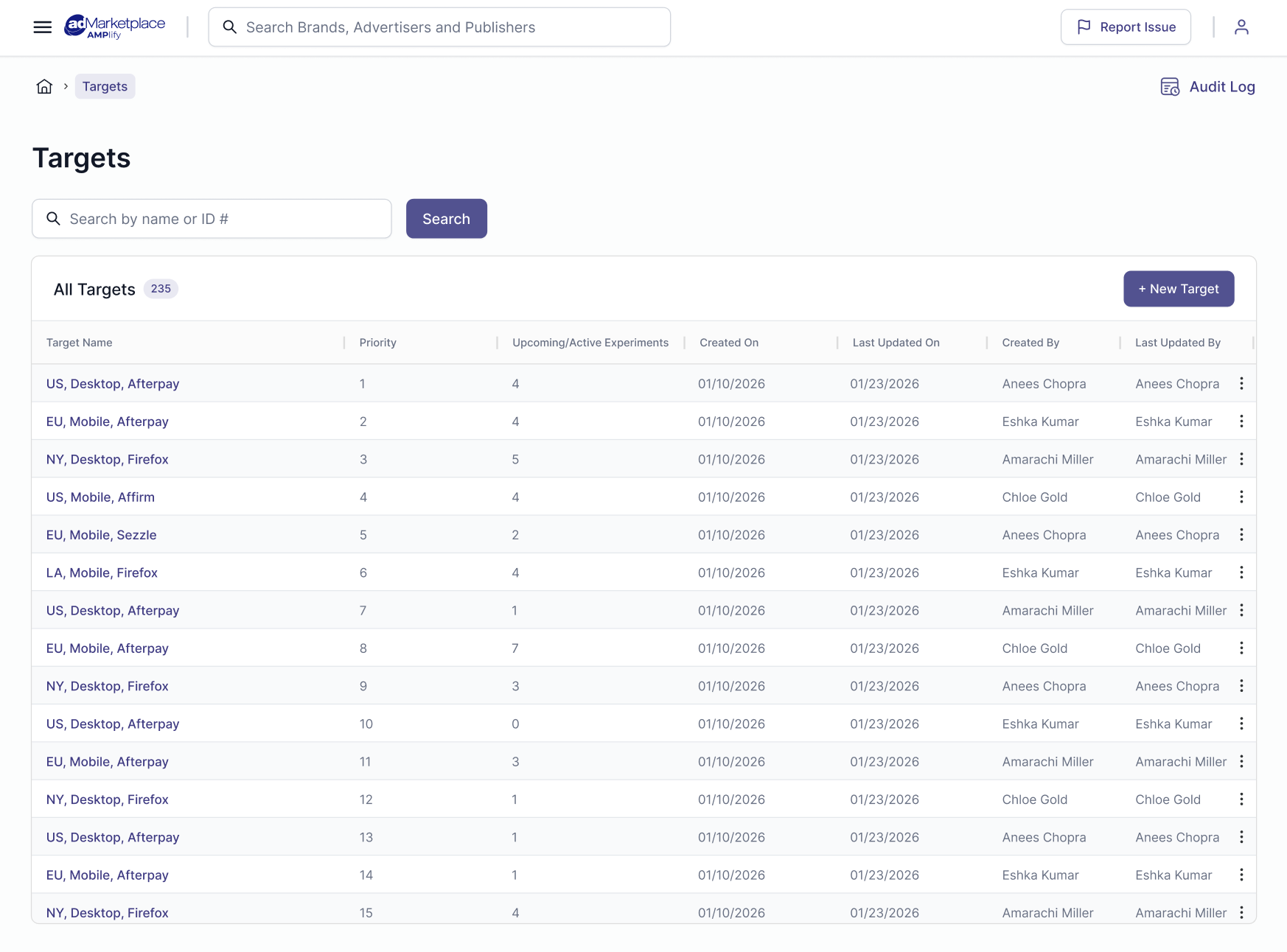
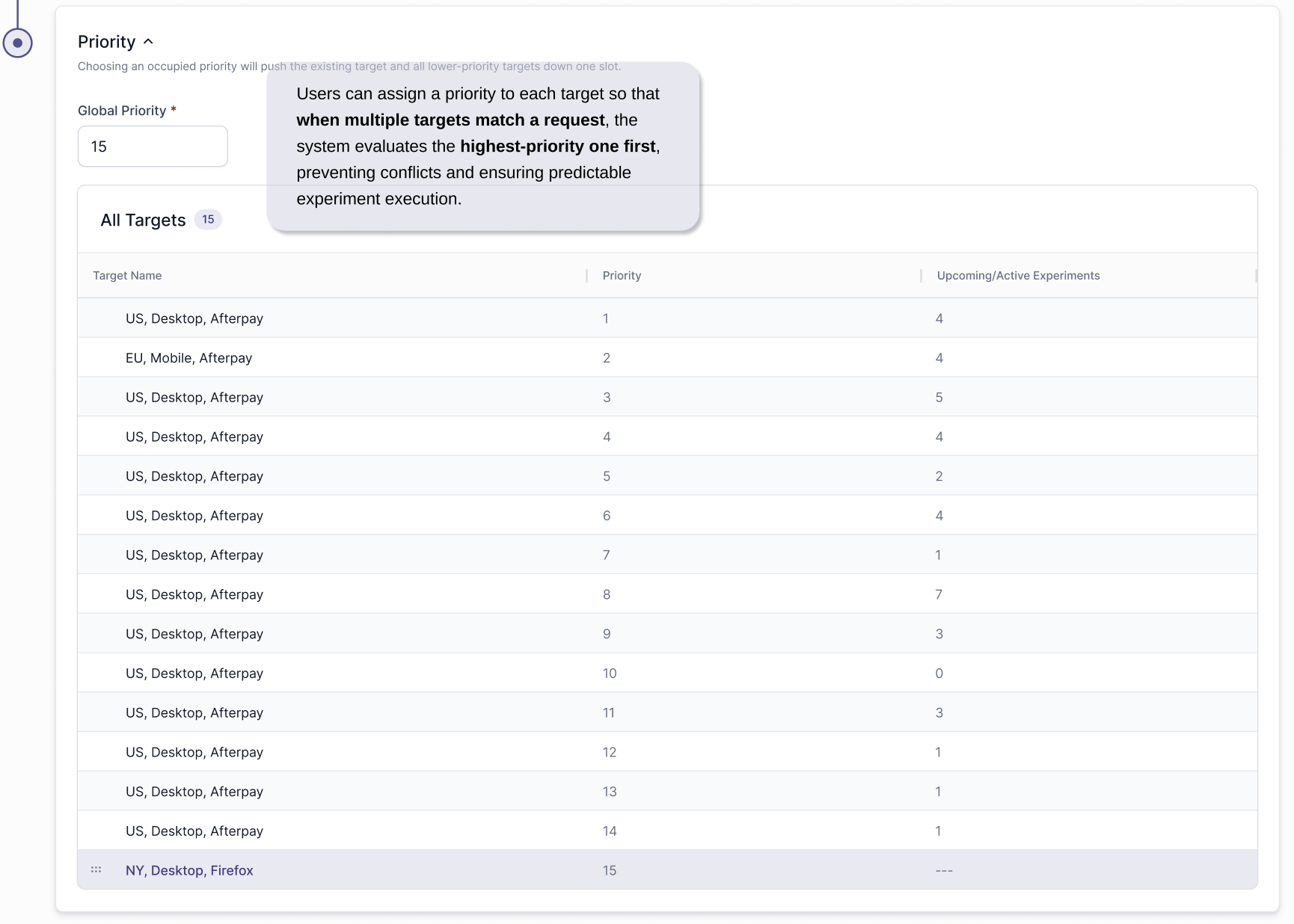
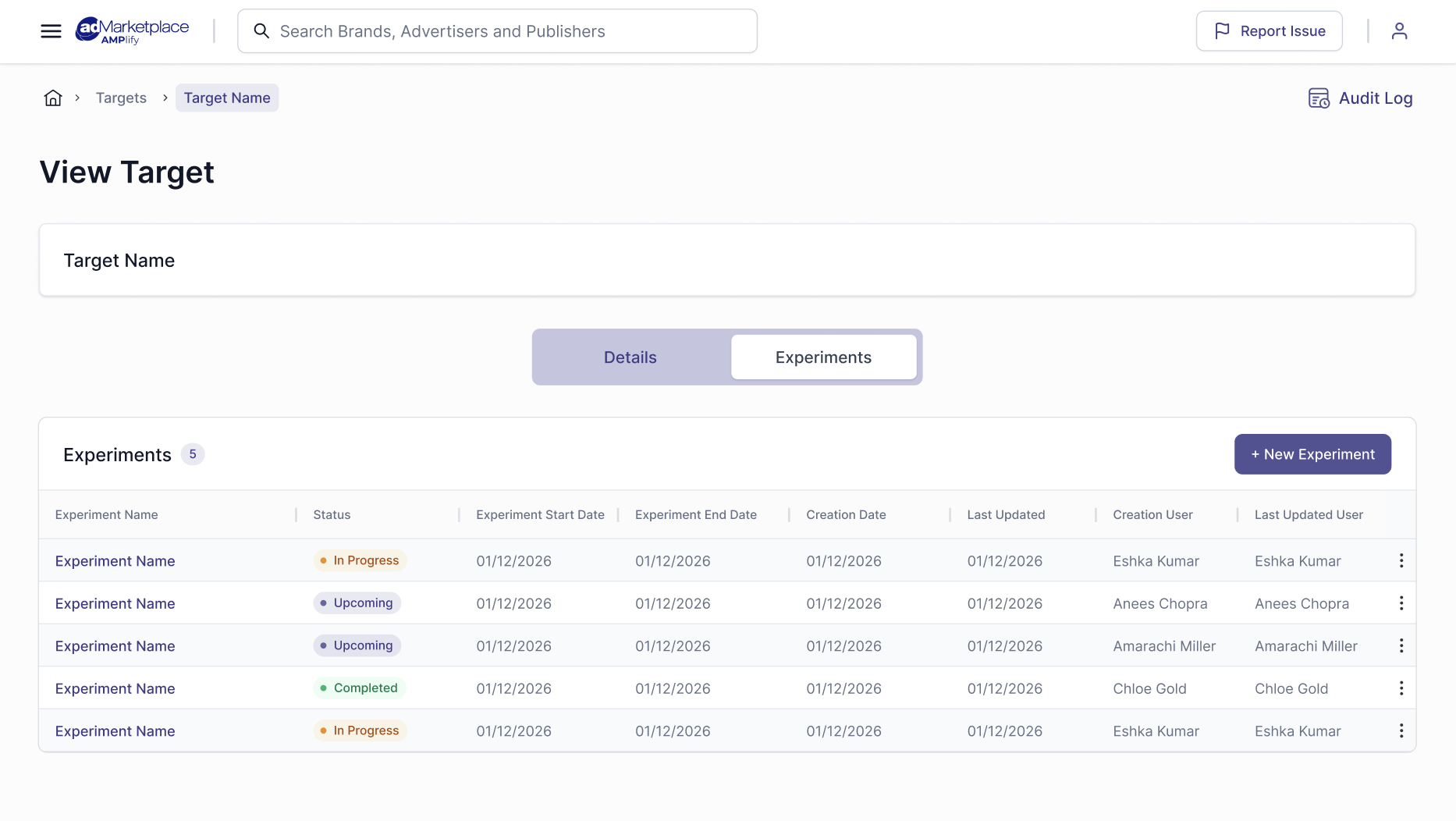
We separated target creation and experiment creation into two distinct flows, and gave both Targets & Experiments their own grid hub. One for targets, and an Experiments grid per Target created to present all the experiments under that Target. Targets are defined once with clear boundaries and priority logic, and experiments are created within those targets. This structure reduces repetition, enforces accuracy, lowers cognitive load, and allows experiments to scale cleanly while remaining tightly controlled by their associated target.
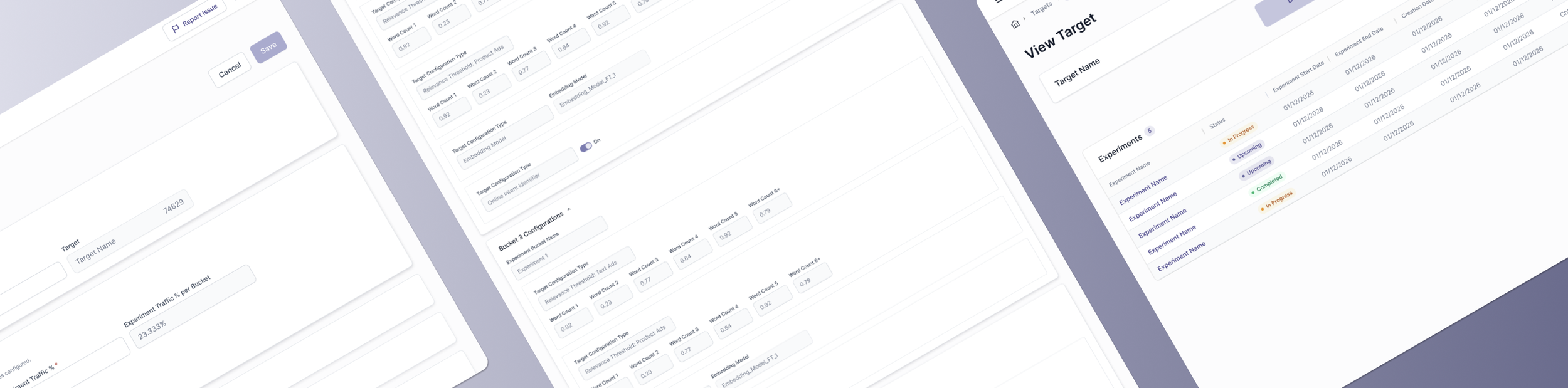
GLOBAL TARGET HUB
TARGET CREATION
EXPERIMENTS UNDER A TARGET
EXPERIMENT CREATION